Top 9 Python Machine Learning Tools in 2023

First things first: what is Machine Learning?
While there still might be some confusion about what exactly Machine Learning is and isn’t, what we know for sure in 2023 is that we all need to get the hang of it. Broadly speaking, Machine Learning is a field of Computer Science that attempts to solve problems by letting the computers ‘learn’ patterns present in the data and build models of reality. These Machine Learning models can subsequently be used for various predictive tasks and automatic decision-making.
Let’s have a quick overview of what are the basic ingredients in every Machine Learning pipeline. Every project starts with raw data, which needs preprocessing. Depending on which Machine Learning model is used, the step of feature extraction might also be necessary. The training of the model is done using said features and if its performance is satisfactory, it can be used for making predictions on future data.

Machine Learning pipeline example
Why is Python a good choice for Machine Learning?
Python is an open-source programming language, characteristic for its large development community and ubiquitous across numerous different industries. Ever since 2017, it has ranked as the most used programming language, according to the Institute of Electrical and Electronics Engineers annual analysis. Part of this popularity is thanks to its key role in building new technology centered around various machine learning applications. In this article, we will explore a selection of the best Python-based open source Machine Learning tools available today. When compared to programming languages with similar scope, such as R and MATLAB, there is no question that Python is a clear winner.
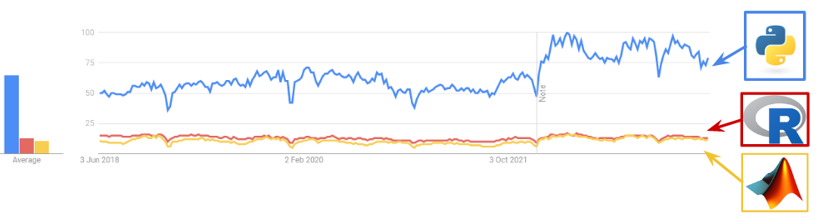
Overview of programming language popularity since 2018.
(Data source: Google Trends)
What Python libraries do I need to know for Machine Learning?
Currently available Python tools for Machine Learning are mostly in the form of libraries, which are collections of built-in code. The libraries presented here are the ones necessary for comprehensive overview of any given Machine Learning pipeline: from basic data wrangling to model fitting and complex predictions post-processing. Here is the complete list of Python libraries frequently used in the field of Machine Learning:
- Pandas
- NumPy
- Scipy
- Statsmodels
- Scikit-learn
- TensorFlow
- Keras
- PyTorch
- XGBoost
We will now explain each of these in more detail to provide the context in which they are used. The list is roughly ordered from the more general-purpose tools towards the more specialized ones, which are also considered to have a steeper learning curve and are therefore intended for more advanced users.
1. Pandas
First things first: to find a way to store and preprocess the data we feed the machine learning models. Pandas is a library specialized in data manipulation and analysis, making it an indispensable tool for any machine learning pipeline. Pandas introduces a data type called DataFrame to store data, which assumes structured data, such as:
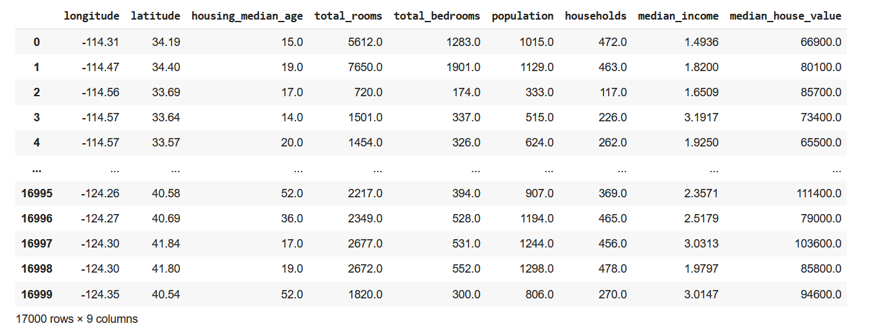
Example of a Pandas data frame containing structured data
The library offers a rich set of functions for data cleaning, transformation, and aggregation. Thanks to its simplicity and readability, it is helpful both for novices, as well as more experienced programmers coming from an SQL or MATLAB background. Moreover, Pandas seamlessly integrates with other Python libraries, allowing easy integration into machine learning pipelines.
2. NumPy
Pandas is often inseparable from NumPy, despite its core difference in data representation. Shorthand for Numerical Python, NumPy is a fundamental Python library extensively used thanks to its fast data processing, crucial for many machine learning applications. The possibility of having multi-dimensional arrays as objects simplifies the implementation of any mathematical operations. NumPy's comprehensive collection of various mathematical functions, random number generators, and linear algebra routines makes it indispensable for machine learning.
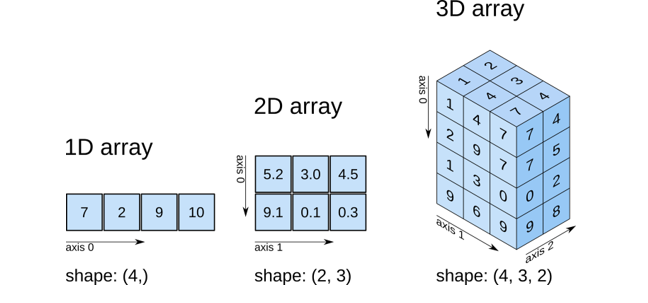
Source: https://predictivehacks.com/tips-about-numPy-arrays/
3. SciPy:
SciPy is another crucial building block for data processing and any in-depth approach to machine learning. Its modules containing a wide range of fundamental operations related to statistics (scipy.stats) and linear algebra (scipy.linalg), but also spectral analysis with Fourier transform (scipy.fft), advanced filtering (scipy.signal), interpolation (scipy.interpolate), or sparse data representation (scipy.sparse). It also includes implementations of various regression and clustering algorithms, thus enabling its use in both supervised and unsupervised machine learning use cases.
4. Statsmodels
Built as an addition to SciPy, statsmodels is a module implementing tools for estimation and inference of statistical models. Whether a user requires a simple linear regression model, a generalized linear model, or a full-scale time-series analysis (hypothesis tests, auto-regressive or state-space models), statsmodels has it covered. Another advantage of statsmodels are the functions aimed at monitoring the quality of both data (influential observations and outliers, heteroscedasticity) and models (residual analysis, goodness-of-fit tests). Additionally, it has seamless integration with pandas DataFrame objects, which means data handling and any model training can be streamlined without type conversion.
5. Scikit-learn
Scikit-learn is one of the first libraries offering a rich set of machine learning algorithms, and still one of the most popular ones. Envisioned to be used to develop full machine learning pipeline, Scikit-learn simplifies the process of building and evaluating models, making it an ideal choice for both novices and experienced users. The library provides modules for data preprocessing, feature selection, model selection, and model evaluation, therefore enabling end-to-end machine learning workflows. In fact, scikit-learn probably deserves an article of its own. Everyone in the field has seen at least some code using scikit’s cross-validation (sklearn.model_selection.cross_validate).
6. TensorFlow
Google’s TensorFlow stands as one of the most popular end-to-end open-source frameworks for machine learning and deep learning. What distinguishes it from previously mentioned tools is the comprehensive and flexible ecosystem that allows users to build and deploy machine learning models efficiently. The main value of TensorFlow is its efficient computation on tensors, especially if being run on specialized hardware (tensor processing unit, TPU). TensorFlow gained its popularity in part due to its extensive collection of APIs, its collection of reusable deep learning model components, and definitely TensorBoard, a visualization tool for monitoring the model training progress. For example, one can construct a deep neural network using tf.layers, optimize its weights with tf.optimizers and tf.losses and monitor and evaluate the model with tf.metrics: all in under 15 minutes.
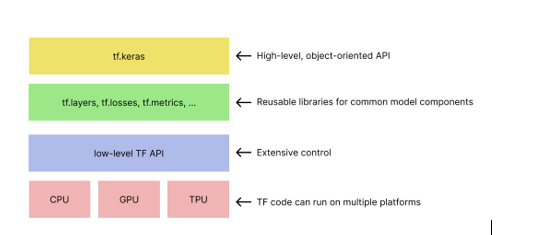
Toolkit hierarchy of TensorFlow.
Data source: https://developers.google.com/machine-learning/crash-course/first-steps-with-tensorflow/toolkit
7. Keras
While originally Keras was designed independently of TensorFlow, Keras is now an integral part of TensorFlow (starting from TensorFlow v2.0). However, it can still be found used with other backend frameworks, like Theano or Microsoft Cognitive Toolkit. What Keras brings to all of these frameworks is a high-level API containing prebuilt layers, activation and loss functions. Since its tight integration with TensorFlow, users can get the best of both worlds: simplicity and the intuitive approach of Keras on top of TensorFlow’s optimized computational performance and access to low-level details, if needed.
8. PyTorch
Although primarily known for its application in Natural Language Processing, Facebook’s PyTorch is similar in versatility and computing efficiency to TensorFlow, and in simplicity to Keras. PyTorch appeared slightly after TensorFlow, but was able to pick up its share of users thanks to a more ‘Pythonic’ way of interacting with modules, especially obvious when it comes to debugging, for which in TensorFlow you have to bend over backwards. Previously limited visualization in PyTorch’ tool Visdom has been improved since PyTorch 1.2.0 included TensorBoard in their release.
9. XGBoost
XGBoost is a more specific library than the previously mentioned ones: it implements the gradient boosting algorithm. The gradient boosting algorithm is renowned for its exceptional performance and accuracy in machine learning competitions on Kaggle and elsewhere. What XGBoost library brings is an optimized and scalable framework for efficient training and prediction of gradient boosting models, which is otherwise costly in both computing power and time. Thanks to its often stellar performance, XGBoost is a popular choice to obtain the off-the-shelf baseline performance on a new dataset for both regression and classification tasks.
As we have seen in this article, Python has established itself as a go-to language for machine learning, thanks to its rich ecosystem of well-documented, open-source tools. Whether you need to preprocess data, train a neural network, or analyze results, one of these open-source machine learning tools - or more often their combination - are your best bet.